Ordering fields
Fields in the Omni model do not currently allow free-form ordering but instead operate in the following framework:| Object | Order | Re-arrangeable? |
|---|---|---|
| View columns (schema dimensions) | Database column order | No |
| Shared model dimensions | Saved by default | Yes, on save |
| Workbook/branch model fields | Saved by default | Yes, on save |
| Measures | Saved by default | Yes, on save |
| Filters | Saved by default | Yes, on save |
Interleaving between these groupings is not currently supported.
Naming dimensions
Dimension names must be unique within any given view (no same names). Names may use characters a-z (no capital letters), 0-9, or underscores, and start with a letter. Additional parameters are nested under the dimension with one tab (two spaces) of indention, for example:Field naming
Permissing field values with user attributes
There may be situations where you need to control who sees the values for specific fields. To accomplish this, use user attributes in a dimension’ssql definition to mask or hide values as needed:
Hiding field values
Hashing field values
Filter-only fields
Filter-only fields are often used alongside templated filters to create fields for more specific use cases that only operate as filters, often to dynamically filter fact tables or subqueries.Handling schema field adjustments
Raw schema field names may need to be adjusted to work correctly in Omni for analytics. This can happen due to type casing issues, timezone adjustments, or other complex reasons. You can account for this by creating an additional field, for example:Creating a new adjusted field
${} syntax:
Adjusting field in place
Creating fields from JSON
This section only applies to modeled fields. Fields defined in raw SQL are not supported.
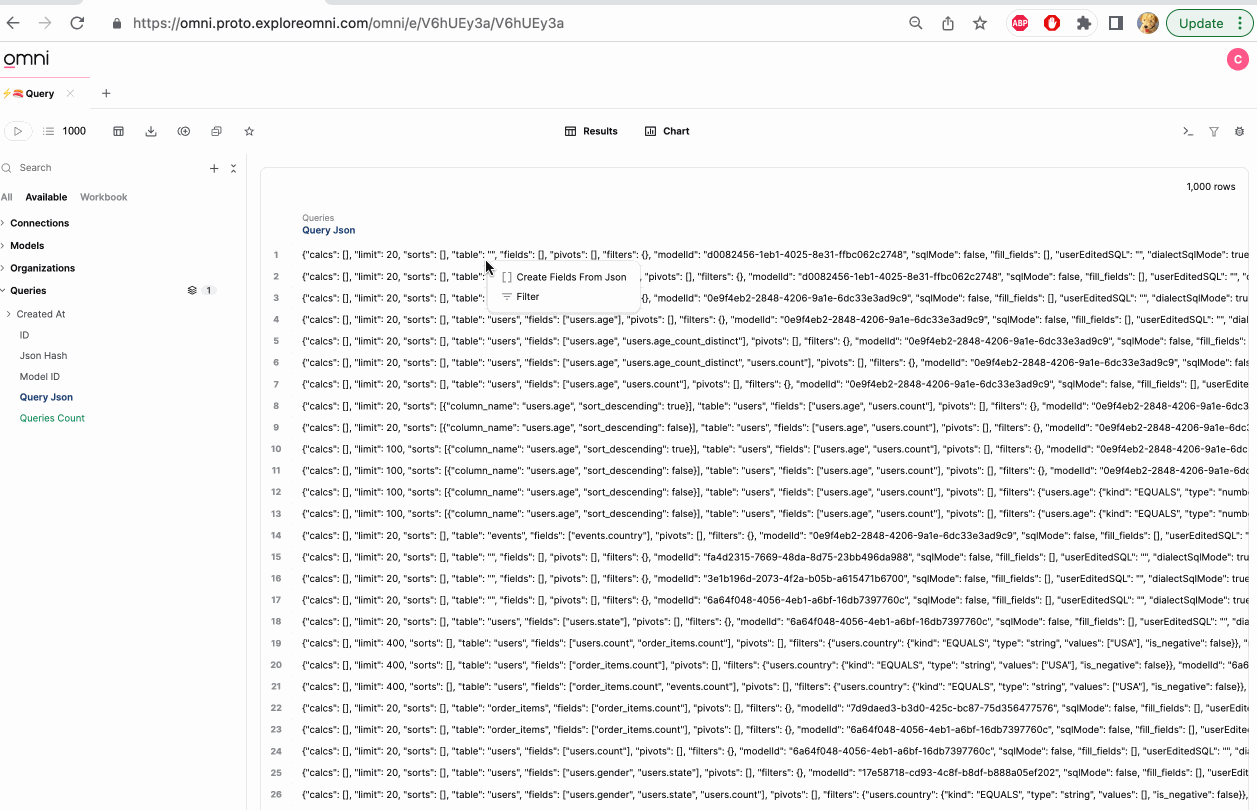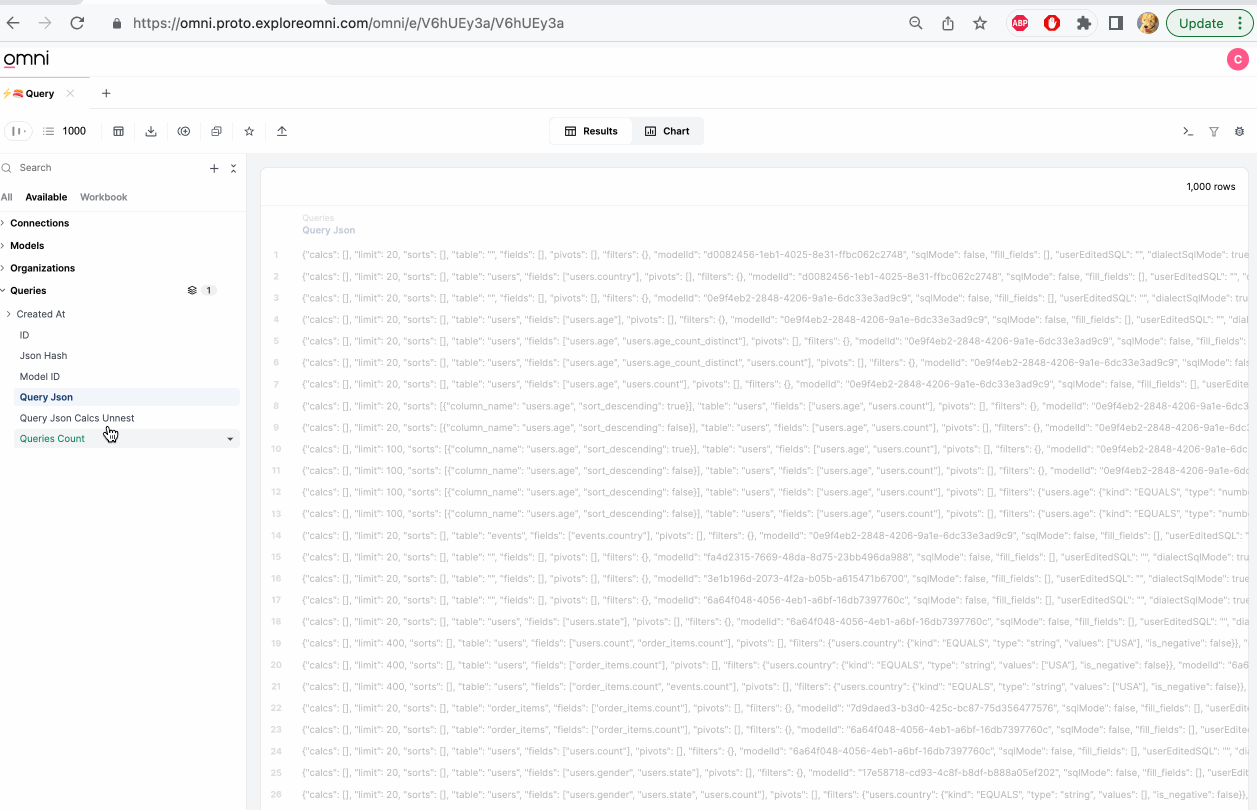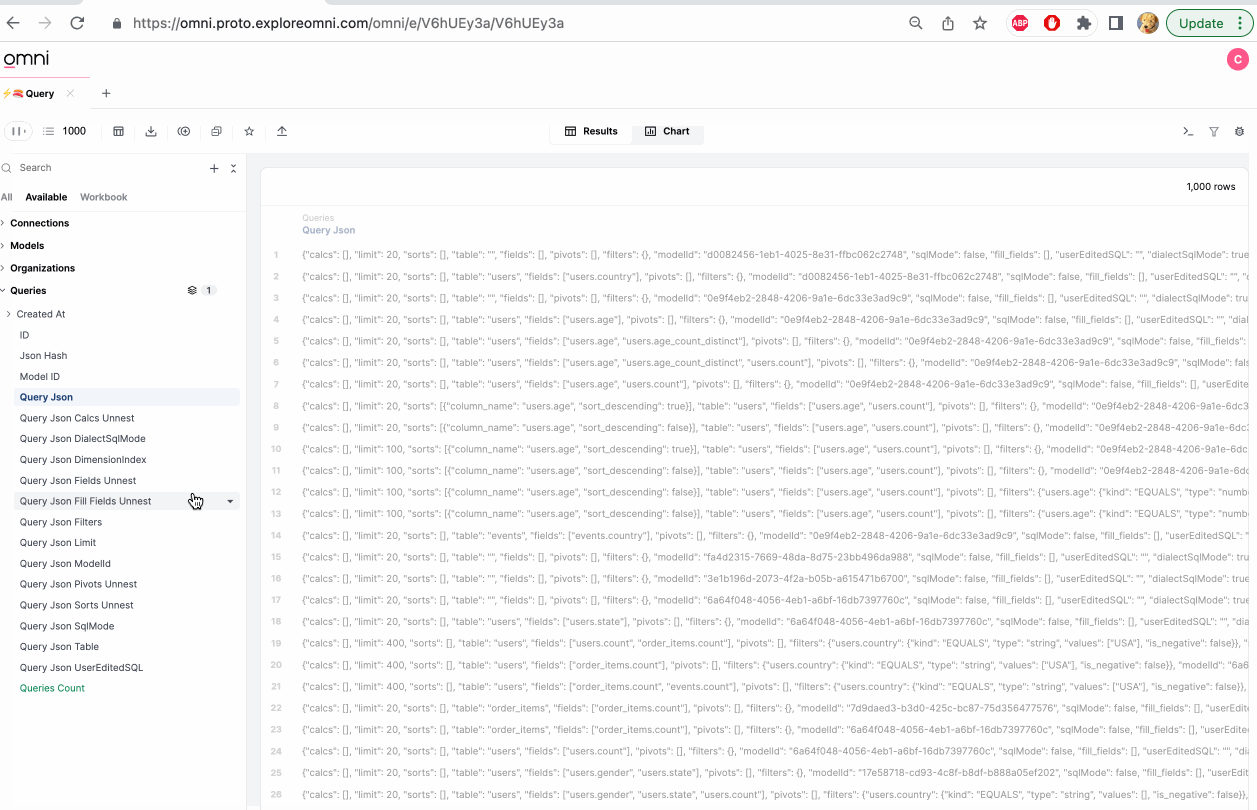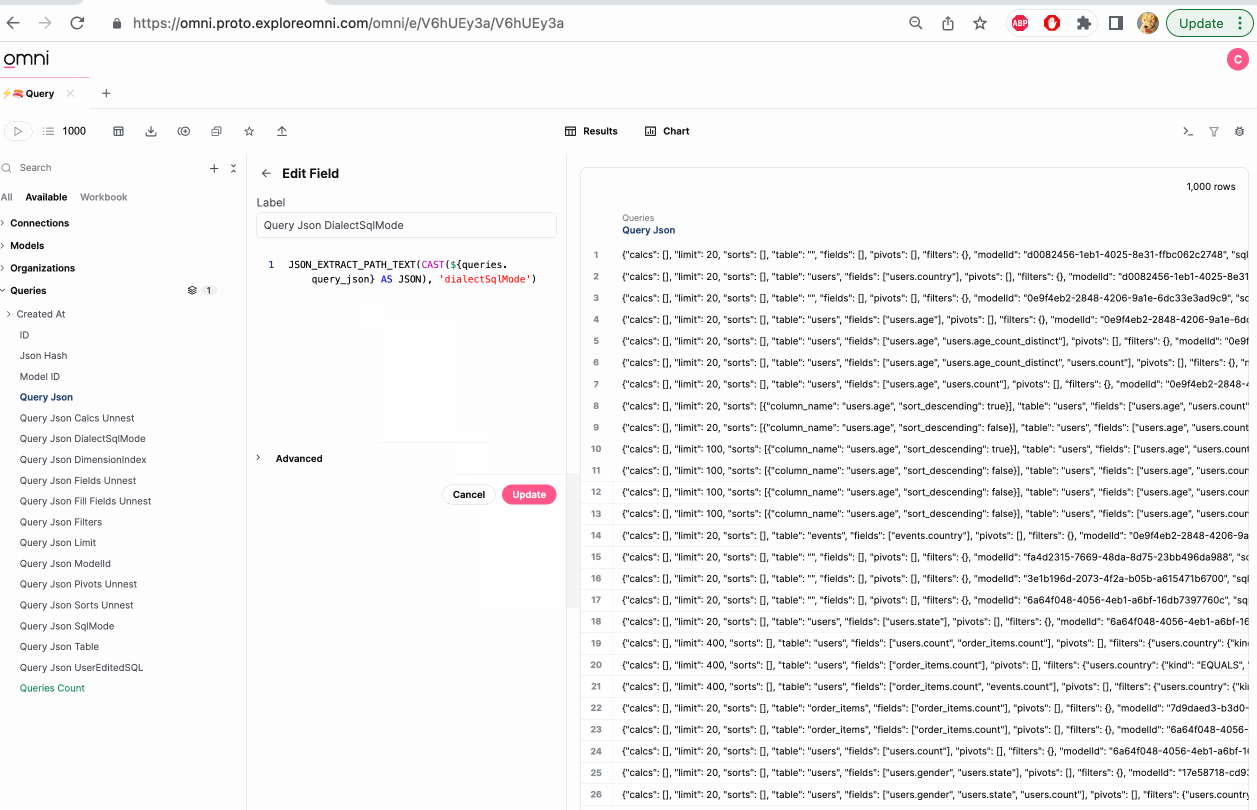
When parsing JSON, you may need to manually cast fields to the correct data type after they are created. For example, timestamp fields may be created as strings.
Level of Detail (LoD) Fields
Level of Detail (LoD) fields let you control the exact granularity at which an aggregation is computed, independent of how the rest of the query is grouped. Use thelevel_of_detail parameter on a dimension to define it as an LoD field.