Getting started with modeling
Modeling in Omni is done in a layered approach. The system manages three core modeling layers:
- A schema model that mirrors the database
- A shared, virtualized data model for global business metrics and definitions
- A workbook model for ad hoc analysis that extends the core data models
As metrics are refined, they can be promoted from a workbook into your organization's shared model, and, eventually into the database schema beneath Omni.
Core philosophies
The Omni data model is a layered one. The schema model reflects the raw database, with subsequent layers above. The shared model represents the universal, governed data model that each new workbook is based on. Finally the workbook model extends the schema model and shared model. This is a simple way to think about modeling in Omni:
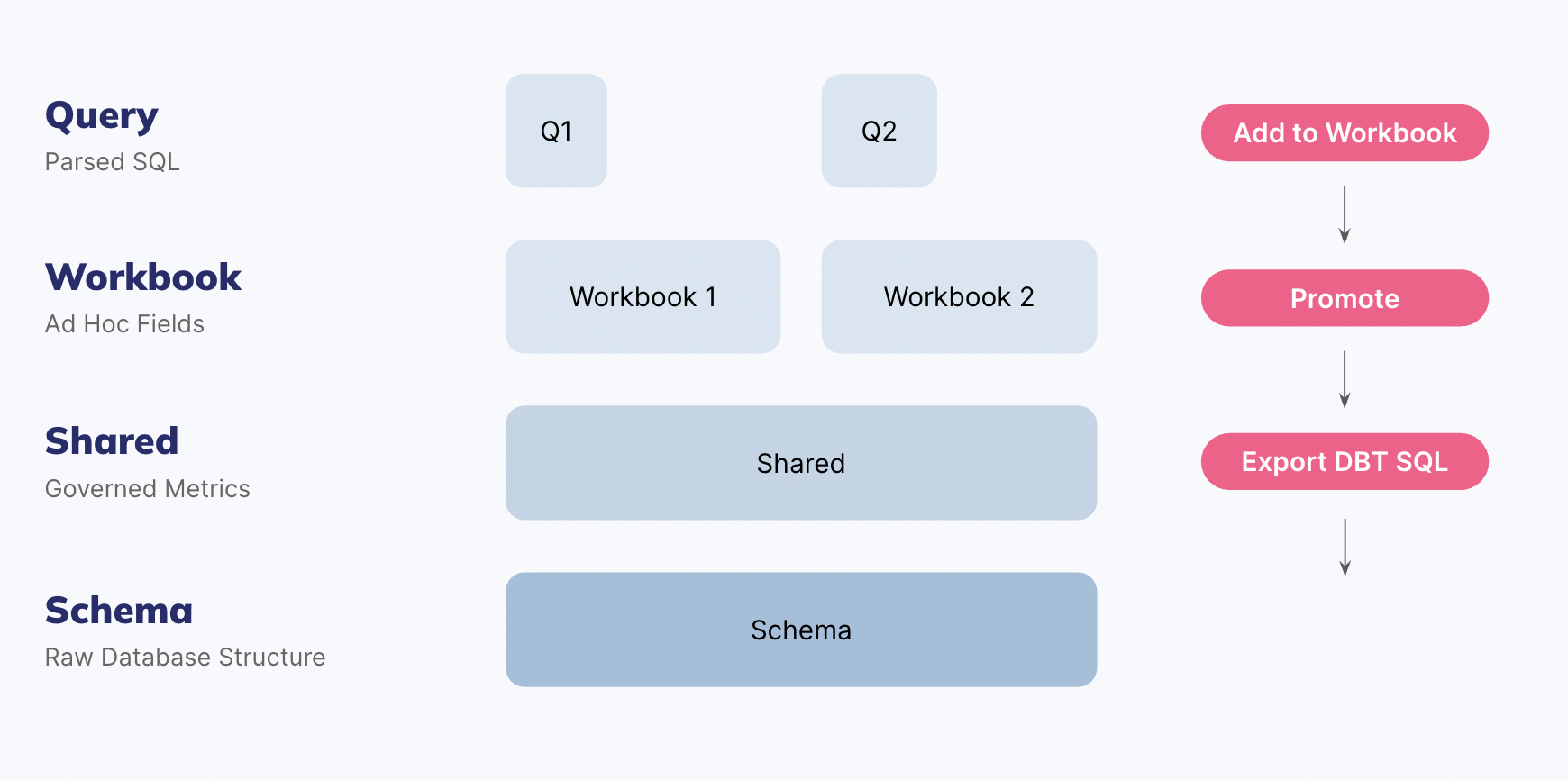
When developing a data model in Omni, it's often best to start by modeling in the workbook. Joins and fields can then be promoted to the shared model for consumption by all workbooks.
Model Structure
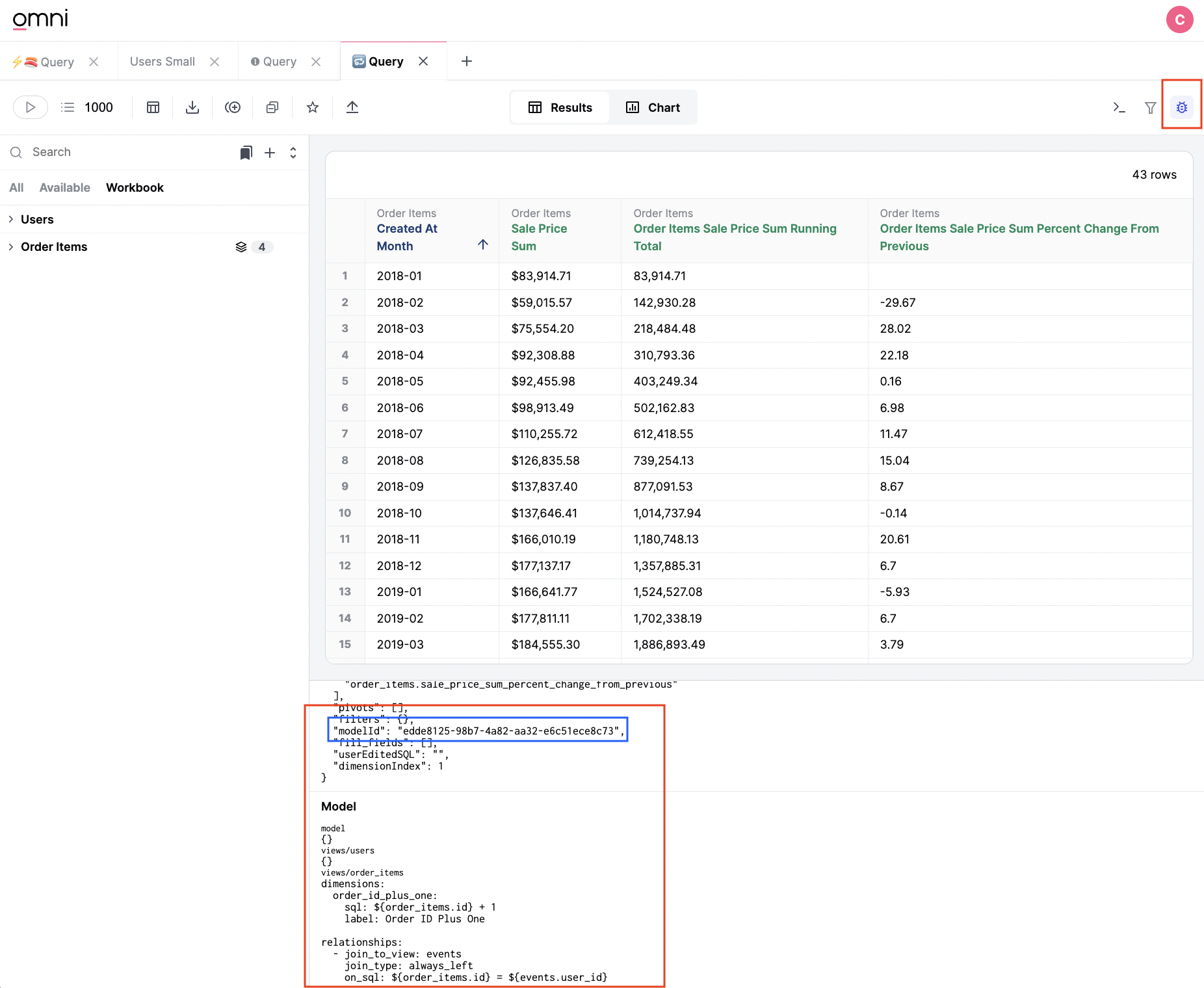
See docs on schema model and shared model. If the schema looks out of sync with the database, simply refresh the schema in the UI. Workbook models are not available in the UI, but can be viewed through the debug in a workbook. Eventually these will be available individually and batched.
An example workbook data model is shown below. Note you can even grab the modelID from the query structure to view the model in the model IDE (shown in blue):
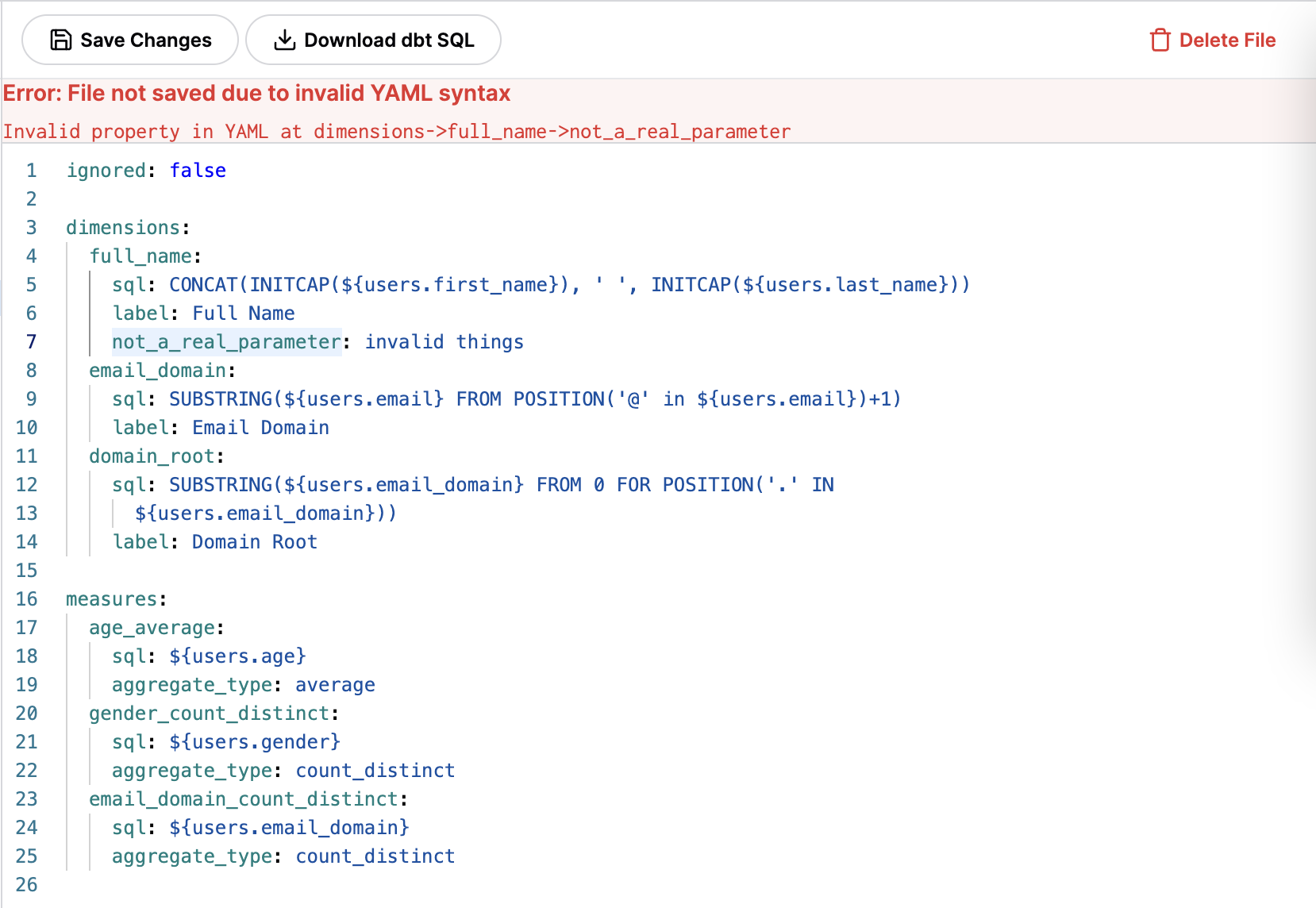
Validation
Omni models have strong validation. Errors in style and substance are often rejected during the save process. This will be softened over time and the UX will be improved, but be aware that invalid code may be rejected on save in the data model.
Field typing is implicit in Omni based upon the dialect and functions applied. To change types, simply cast fields in SQL.
When the schema model is updated, breakage can occur in layers above. The model IDE will provide pointers to broken field references to resolve any issues, for example when columns are deleted beneath Omni.