Measures
Measures describe how to aggregate data in Omni. Measure are either aggregates of dimensions (max of profit, sum of revenue) or transformations on top of other measures (sum of profit / count of users).
page_count_average:
sql: ${orders.page_count}
aggregate_type: average
total_revenue:
sql: ${orders.sale_price}
aggregate_type: sum
percent_email:
sql: |-
${count_email_sum}
/
${count}
first_reply_date:
sql: ${replies.received_at[date]}
aggregate_type: min
Parameters
aggregate_type:
total_revenue:
sql: ${orders.sales_price}
aggregate_type: sum
revenue_per_order:
sql: ${orders.total_revenue} / ${orders.count}
- Aggregate defines the aggregation method for an underlying dimension
- For aggregates not offered by default, measures can be written entirely in SQL (
sql: MEDIAN(${orders.price}) - Current aggregates offered:
countcount_distinctlistsumminmaxaveragemedianpercentile- Example:
perc_75_age:
sql: ${users.age}
aggregate_type: percentile
percentile: 75
- Example:
sum_distinct_on- Example:
sum_distinct_example:
sql: price
aggregate_type: sum_distinct_on
custom_primary_key_sql: id
- Example:
average_distinct_onpercentile_distinct_onmedian_distinct_on
aliases:
field_name:
sql: ${'"FIELD_NAME'}
aliases: [OLD_FIELD_NAME]
Similar to table level aliases, occasionally a field name may change in your database, which can cause content to break. To fix this, we can add aliases: to the field in question pointing references from the old field name to the updated field name, restoring content and eliminating content related errors. This behaves similar to table level aliases, as shown below:
colors:
Maps a color to the measure when it's used as a series in a visualization. This allows you to maintain consistent coloring for the measure across visualizations. You can also model colors for dimensions.
colors:
series: green # The color to be used in visualizations when the measure is used as a series
colors:
series: rgb(0, 0, 255) # Specifies blue using RGB
colors:
series: rgba(0, 0, 255, 0.3) # Specifies blue with opacity using RGBA. HSLA is also supported.
colors:
series: hsl(120, 100%, 50%) # Specifies green using HSL
colors:
series: "#000000" # Specifies black using hex code. Must be quoted.
The colors parameter must contain a child series parameter, which specifies the color to be used. The color can be specified using any legal CSS method.
description:
full_name:
description: Full name based on first_name, last_name in CRM
- Metadata about the field, made available in the workbook UI
- Omni expects unquoted text (quotes will be removed / ignored)
display_order:
count:
aggregate_type: count
display_order: 1
- Omni expects a whole number
- This will override the sort order for the field picker, inside the field's grouping (i.e. inside a given view)
display_orderwill supersede alphabetical sorting
- Note this will not move measures above dimensions
- For example, if two fields in order_items are given
display_order: 1they will float to the top of the measure list in order_items, then sort alphabetically, and the remaining fields would be sorted alphabetically - To rearrange views,
display_ordercan be used at the view level - For fields inside groups using
group_label, the group will be ranked with the min of all the fields in the group (i.e. if there are 3 fields withdisplay_orderof 4, 5 and {empty}, the group will have adisplay_orderof 4)
drill_fields:
count:
drill_fields: [view.field1, view.field2]
aggregate_type: count
other_count:
drill_fields: [tag:my_tag]
aggregate_type: count
count:
drill_fields:
[
users.id,
users.full_name,
users.email,
users.age,
users.state,
users.country,
"users.created_at[date]"
]
aggregate_type: count
- Drill fields allow for curation of the drilling behavior for a given measure, using an array of fields for the subsequent query
- Note to pull in date fields, they must be quoted per the example above
- Empty
drill_fieldswill remove the drill from the measure (i.e.drill_fields: []) - Control is also available in the workbook in the edit field workflow
- Filters on a dashboard or workbook based on a measure are removed from drill queries
- most drill queries produce large numbers of rows, resuling in smaller measure values which can appear, confusingly, as an empty drill table
- Drill down on filtered measures will explicitly bring the measure filters into the query rather than the aggregate (ie as query filters not measure filters)
drill_queries:
my_fun_measure:
sql: ${field_we_aggregate}
aggregate_type: sum
drill_queries:
First Drill for Top 10: # The drill query key can be a human-readable label
fields:
[
field_1,
field_2,
...
]
base_view: view_name_1 # this table will act as the `from` clause of the query
limit: 10
sorts:
- field: view_name_1.field_1 # note sort requires full scoping
- field: view_name_1.field_2
desc: true
Customer Details: # Another example with a descriptive label
fields:
[
customer_name,
customer_email,
registration_date
]
base_view: customers
limit: 20
sorts:
- field: customers.registration_date
desc: true
second_drill_that_references_more_than_one_view:
fields:
[
view_name_1.field_1,
view_name_1.field_2,
view_name_2.field_3,
...
]
base_view: view_name_1
limit: 5000
- A measure can have multiple drill queries set, which will appear when a user clicks to drill, offering various pathways to dig in deeper
- These give additional flexibility over a
drill_fieldsset, allowing a user to specify the underlying query getting run on drill, including changes like limits, sorts, filters and base_views. - If you want to reference fields from multiple views, ensure that a relationship exists between your base view and the other referenced views so that your drill down will render as expected
- To get the structure + syntax of a query, build a query in a workbook and open up the inspector and scroll down to the "Query Structure" settings
- Note: drill queries do not require underscores in their names which offers more flexibility in naming.
ignored:
total_users:
ignored: true
- Removes the field from the UI and prevents references to the field
- Often used to 'remove' fields from the raw database schema
- Note ignored fields are still available through the SQL runner
- Expects 'true' or 'false'
filters:
See full page on filter syntax here.
count_california_seniors:
aggregate_type: count
filters:
age:
greater_than_or_equal_to: 65
state:
is: California
count_ny_or_nj:
aggregate_type: count
filters:
state:
is: [New York, New Jersey]
### note filtered measures can point to raw columns or modeled fields
dimensions:
is_big:
sql: ${employee_count} > 100000
measures:
count_large:
aggregate_type: count
filters:
is_big:
is: true
- Filtered measures can be built using aggregation alongside a dimension filter
- Multiple filters can be added in the filter clause, and multiple values for a given filter can be added using array syntax
- For more complex filter logic, it's often best to build a boolean filter to capture the complexity:
complex_dimension_example:
sql: ${state} = 'California' OR ${age} > 65
count_complex_logic:
aggregate_type: count
filters:
complex_dimension_example:
is: true
- Additionally filtered measures can use all of the complexity of query views, like filter by query. Here we filter user_id to the top 10 users by total spend, descending, and use that in our count:
count_top_10_users:
format: NUMBER
aggregate_type: count
filters:
id:
field_name_in_query: order_items.user_id
query_structure:
fields: [ order_items.user_id, order_items.sale_price_sum ]
base_view: order_items
limit: 10
sorts:
- field: order_items.sale_price_sum
desc: true
topic: order_items
format:
sale_price:
format: currency_2
revenue:
format: big_2
created_at:
timeframe_metadata:
month:
format: "%Y-%m-%d"
- Sets default formatting for numbers in Omni, using a named format (see below)
- Each format is two decimal places by default, except id, which does not include decimals
- To set decimal length explicitly on a format, simply add {number_of_digits}, up to 4 digits
- Examples:
format: number_4,format: big_1,format: usdaccounting_0 - When decimal length is not set, decimals will be truncated to the shortest possible length for each row
- Examples:
- Formats can also be set on a per-query basis using visualization configuration, using the same format types
- There is no current control for
.and,delimiters in numerics
Formats are applied after the SQL, thus will not impact grouping. To handle grouping with truncation use ROUND() or FLOOR().
- Numeric formats:
number: 1,234.50 (number_2)percent: 24.4% (percent_1)id(numbers with no commas): 123450billions: 1.20B (billions_2)millions: 5.6M (millions_1)thousands: 8.90K (thousands_2)big: 5.60M; 1.23K; 12.23 (big_2)millionsif >1M;thousandsif >1000; otherwisenumber
- Time formats:
- Time formats use d3 time formats (link)
- Individual timeframe elements can be formatted using
timeframe_metadata:(see example above) - Examples:
"%Y-%m","%Y-%m-%d","%Y-%m-%d %H:%M:%S"
- Currency formats:
- By default currencies will use USD through the app, config is coming to change global defaults
- Right now each format can be adjusted to USD, EUR, and GBP
- It's recommended to use explicit currency formatting for now
accounting,usdaccounting,euraccounting,gbpaccounting: $(1,234.50) (usdaccounting_2)currency,usdcurrency,eurcurrency,gbpcurrency: -£1,234.50 (gbpcurrency_2)bigcurrency,bigusdcurrency,bigeurcurrency,biggbpcurrency: €5.60M; €1.23K; €12.23 (biggbpcurrency_2)financial: (1,234.50) (financial_2)- Note financial does not contain a currency mark
group_label:
order_count:
group_label: Important Fields
- This will nest a group of fields in the field picker for curated organization
- Omni expects unquoted text (quotes will be removed / ignored)
- Note measures and dimensions will still be in separate sections in the field picker under each view
hidden:
sum_excluded_revenue:
hidden: true
- Remove the field from the UI. Still referenceable in the model; hidden in the workbook UI.
- Expects 'true' or 'false'
label:
full_name:
label: Full Name
- Label will override the field name for all UI appearances of the field
- Omni expects unquoted text (quotes will be removed / ignored)
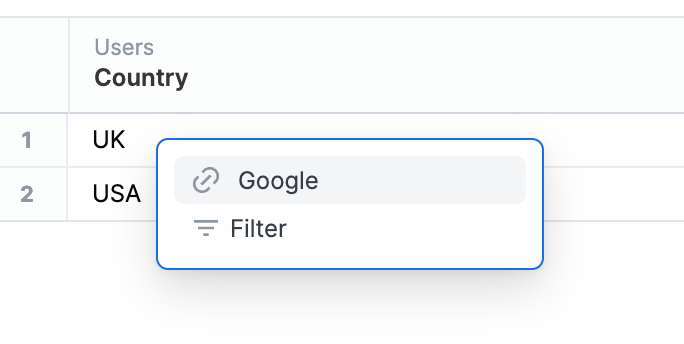
links:
country:
links:
- url: https://www.google.com/search?q=${users.country}
label: Google
id:
sql: '"ID"'
format: ID
links:
- url: https://sandbox.omniapp.co/dashboards/YX-irW2S/user+lookup?f--users.id=%28%27kind%21%27EQUALS%27%7Etype%21%27number%27%7Evalues%21%5B%27${ecomm__users.id}%27%5D%7Eis_negat*%7Eis_inclus*%29*ive%21false%01*_
label: User Lookup Dashboard
- Links will add an external link to a templated URL into the drill menu
- Omni expects unquoted text, and any field references using
${} - Fields referenced in links will be implicitly added to the query but not shown in the result data unless explicitly included
- Avoid referencing a dimension with more than one value for a given value of the dimension on which the link is defined as it can impact aggregations and seemingly create duplicate rows
- Note for crosslinking dashboards (as per example above), you inject the corresponding field into the filter URL structure; it's often easiest to do this from a filtered dashboard and then swapping in the dynamic link
required_access_grants:
Limits a user's ability to query a field based on an assigned user attribute. The referenced access_grants must already exist in the model file. Refer to the Controlling data access guide for more information.
You can also conditionally allow access by using pipes (|) and commas (,) to create OR and AND conditions.
required_access_grants: [ grant_one ]
# Grant access if conditions are met for either access grant
required_access_grants: [ grant_one|grant_two ]
# Grant access if conditions are met for:
# grant_one
# OR
# grant_two AND grant_three
required_access_grants: [ grant_one|grant_two,grant_three ]
sql:
total_revenue:
sql: ${orders.sales_price}
aggregate_type: sum
revenue_per_order:
sql: ${orders.total_revenue} / ${orders.count}
average_revenue:
sql: AVG(${orders.sales_price})
- The core declaration of the field definition. Best practice dictates using field references over raw database columns when calling other fields/dimensions. Other fields can be called wrapping view.name in
${}, i.e.${orders.id}. - Note that field type is implicit in Omni, and defined based upon the underlying fields database type. To change the type, simply CAST the field (for example,
sql: ${zip_code}::string).
suggest_from_field:
status_list:
aggregate: list
sql: ${status}
suggest_from_field: order_items.status
- By default, filters will run a
SELECT DISTINCT(${field})to populate filter suggestions - In scenarios where that query may be less performant, or in places where developers may want to curate the suggestion list,
suggest_from_field:can be used to suggest via an alternative field's distinct values - Omni expects a field reference, without
${}, for exampleorder_items.status
suggestion_list
status_list:
aggregate: list
sql: ${status}
suggestion_list: [complete, pending]
- By default, filters run a
SELECT DISTINCT(${field})to populate filter suggestions,suggestion_listwill bypass the default behavior suggestion_listcan be used to explicitly set the list of filter options, both for performance reasons, and curation- Omni expects an unquoted list using
[]and a comma-delimited list of the values
tags:
total_profit:
aggregate: sum
sql: ${profit}
tags: [finance, secure]
tags:are currently used for field picker search in the workbook and to curatefields:anddrill_fields:- Tags can be referenced (or searched in field picker) within
fields:ordrill_fields:with the syntaxtag:tag_name - In the future, tags will be used to curate the field list, mask fields, or for other security and privacy configuration
- Omni expects an unquoted list using
[]and a comma-delimited list of the values
view_label:
sum_lifetime_orders:
aggregate: sum
sql: ${user_facts.lifetime_orders}
view_label: users
- This will nest a given field under a different view than it's default parent view, for example, grouping
user_factsfields under theusersview for better organization and discovery
Semi-additive Measures
Semi-additive measures are aggregations that can be added across some dimensions, but not all. Consider an end of day bank account balance. Summing this value across all days for a current balance would show an inaccurate number, as bank balances track an overall number rather than the incremental change from day to day. Leveraging semi-additive measures allows us to still accurately track the sum of this current bank account balance across days, while also cutting by other dimensions that may make sense to sum within a day, such as account type.
These semi-additive measures are possible through the Omni_Dimensionalize function. This function will turn a measure, such as max(${date}) into a dimension, which can then be used for filtering within a given period. The newly converted dimensions are able to be used in subsequent logic to filter other measures and fields within the given query's grouping.
An example below demonstrates first creating a last known date, simply the maximum created at date with the query's grouping, which is then used to check if the given date is equivalent to that max date within the grouping.
dimensions:
last_date:
hidden: true
sql: omni_dimensionalize(max(${created_at}))
is_last_date:
hidden: true
sql: ${created_at[date]}=${last_date[date]}
measures:
semi_additive_sum:
sql: ${sale_price}
aggregate_type: sum
filters:
is_last_date:
is: true
- From this, we can then build a filtered measure that includes this boolean field as a filter.