Dimensions
The dimension is an attribute that describes a row of data. It is used as the primary segmentation and grouping for querying. Dimensions can be date/time, strings, booleans, or numbers. Omni also has helpers for working with nested dimensions like JSON.
Dimension names must be unique within any given view (no same names). Names may use characters a-z (no capital letters), 0-9, or underscores, and start with a letter.
Your schema model will, by default, create dimensions for every column in your database.
full_name:
sql: CONCAT(INITCAP(${users.first\_name}), ' ', INITCAP(${users.last_name}))
label: Full Name
margin:
sql: ${order_items.sale_price} - ${products.cost}
is_special_date:
sql: |-
CASE
WHEN ${orders.created_at[date]} \>= '2022-04-14' AND ${orders.created_at[date]} \<= '2022-05-09'
THEN 'Mothers Day 2022'
WHEN ${orders.created_at[date]} \>= '2022-05-26' AND ${orders.created_at[date]} \<= '2022-06-20'
THEN 'Fathers Day 2022'
ELSE 'Other'
END
timestamp_created_pst:
sql: DATETIME(${marketing_orders_new.timestamp_created}, 'America/Los_Angeles')
timeframes:
- DATE
- HOUR_OF_DAY
- MONTH_NAME
status_groups:
sql: ${order_items.status}
groups:
- filter:
is: [ Cancelled, Returned ]
name: Test
- filter:
is: [ Processing, Shipped ]
name: going
else: Other
label: Status Groups
Field ordering
Fields in the Omni model do not currently allow free-form ordering. They operate inside a framework that looks as follows:
- View's columns (schema dimensions), in database column order, cannot be re-arranged
- Shared model dimensions, in order saved by default, but re-arrangeable on save
- Workbook / branch model fields, in order saved by default, but re-arrangeable on save
- Measures, in order saved by default, but re-arrangeable on save
- Filters, in order saved by default, but re-arrangeable on save
We may evaluate tools for rearranging or reordering fields, but interleaving between these groupings is not currently possible.
Field name
first_name: # the name of the field/dimension
label: Full Name
sql: CONCAT(${first_name}, ' ' ${last_name})
is_from_california:
sql: ${state} = 'California'
- Fields are named as the top level object for a field, followed by a colon
- Subsequent arguments are nested under the field with one tab of indentation
aliases:
Similar to table level aliases, occasionally a field name may change in your database, which can cause content to break. To fix this, we can add aliases: to the field in question pointing references from the old field name to the updated field name, restoring content and eliminating content related errors. This behaves similar to table level aliases, as shown below:
field_name:
sql: ${'"FIELD_NAME'}
aliases: [ old_omni_field_name ]
bin_boundaries:
### Bins of "< 21", ">= 21 and < 65", and "65 and above"
age_bin:
sql: ${users.age}
bin_boundaries: [ 21, 65 ]
label: Age Bins
- This specifies bins or tiers for a given numeric field
- The app expects array syntax to set the bin boundaries
- Bin text cannot be configured, but you could use a CASE statement to set explicitly
- These are only offered for numeric fields,
groupsis the equivalent option for strings
colors:
The dimension color modeling feature is currently in beta. Note that as development continues, the syntax for this parameter may change.
Defines a list of colors to map to specific dimension values. This allows you to maintain consistent coloring for dimension values across visualizations, whether they're on the same dashboard or on different dashboards. You can also model colors for measures.
status:
order_by_field: status_order
colors:
conditions: # List of conditions
- condition: # Required. A condition, specified using filter syntax.
is: Complete
color: green # Required. The color to be used in visualizations when the condition is met
- condition:
is: Processing
color: rgb(0, 0, 255) # Specifies blue using RGB
- condition:
is: Pending
color: rgba(0, 0, 255, 0.3) # Specifies blue with opacity using RGBA. HSLA is also supported.
- condition:
is: Shipped
color: hsl(120, 100%, 50%) # Specifies green using HSL
- condition:
is: Cancelled
color: "#000000" # Specifies black using hex code. Must be quoted.
else: red # Optional. Specifies fallback color if no condition is met
Each condition in the list must specify the following:
-
A condition specified using filter syntax. Note: The condition must be a child of the
conditionkey, for example:colors:
conditions:
- condition:
is: Processing # Correct
color: blue
- condition:
is: Shipped # Incorrect
color: "#000000"Currently, only the
is:syntax is supported for conditions. The full filter syntax will be added in future updates. -
A
color, which can be specified using any legal CSS method
You can also set a fallback color using the else parameter, which will be applied to values that don't meet any condition in the list. This parameter must be a child of colors, not conditions:
colors:
conditions:
- conditions:
...
else: red
convert_tz:
created_date:
sql: created_date
convert_tz: false
- This specifies that a field does not need to be converted to the query timezone.
- This parameter can only be added to a dimension, and will apply to all the parameterizations of the dimension.
- This is usually the right choice for date or week fields in the database, as the time segments don't make sense to convert.
- Note, timezone conversion in the
sql:is strongly discouraged as there may be challenges on sql generation for complex transformations like dimension fill vis-a-vis timezones
description:
full_name:
description: Full name based on first_name, last_name in CRM
- Metadata about the field, made available in the workbook/dashboard table UI upon hovering over a field with a description, or on right click from the field picker
- Omni expects unquoted text (quotes will be removed / ignored)
display_order:
first_name:
display_order: 1
last_name:
display_order: 2
- Omni expects a whole number
- This will override the sort order for the field picker, inside the field's grouping (i.e. inside a given view)
display_orderwill supersede alphabetical sorting
- For example, if the two fields above in users are given
display_order:they will float to the top of the field list in users, and the remaining fields would be sorted alphabetically - To rearrange views,
display_ordercan be used at the view level - For fields inside groups using
group_label, the group will be ranked with the min of all the fields in the group (i.e. if there are 3 fields withdisplay_orderof 4, 5 and {empty}, the group will have adisplay_orderof 4)
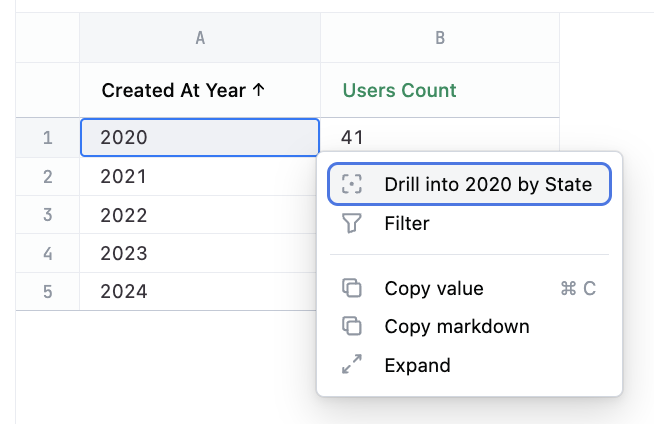
drill_fields:
country:
drill_fields: [state]
created_at:
timeframe_metadata:
year:
drill_fields: [ state ]
group_label: Created At
- Drill fields allow for hierarchical drilling inside a row of the result set
- Dimensional drill will retain the table structure, but add the dimensions as filters, and swap the dimensions for the drill fields
- Empty
drill_fieldswill remove drill from the measure (i.e.drill_fields: [])
filter_single_select_only:
country:
filter_single_select_only: true
- Sets a dimension or filter-only field to only allow for a single-value style filter in workbooks and dashboards
- Only works for string fields and filters
- Especially useful for filter-only fields used as a parameter
format:
sale_price:
format: currency_2
revenue:
format: big_2
created_at:
timeframe_metadata:
month:
format: "%Y-%m-%d"
-
Sets default formatting for numbers in Omni, using a named format (see below)
-
Each format is two decimal places by default, except id, which does not include decimals
-
To set decimal length explicitly on a format, simply add {number_of_digits}, up to 4 digits
- Examples:
format: number_4,format: big_1,format: usdaccounting_0 - When decimal length is not set, decimals will be truncated to the shortest possible length for each row
- Examples:
-
Formats can also be set on a per query basis using visualization configuration, using the same format types
-
There is no current control for
.and,delimiters in numerics -
Note Formats are applied after the SQL, thus will not impact grouping. To handle grouping with truncation use ROUND() or FLOOR().
-
Numeric formats:
number: 1,234.50 (number_2)percent: 24.4% (percent_1)id(numbers with no commas): 123450 (id)billions: 1.20B (billions_2)millions: 5.6M (millions_1)thousands: 8.90K (thousands_2)big: 5.60M; 1.23K; 12.23 (big_2)millionsif >1M;thousandsif >1000; otherwisenumber
-
Time formats:
- Time formats use d3 time formats (link)
- Individual timeframe elements can be formatted using
timeframe_metadata:(see example above) - Examples:
"%Y-%m","%Y-%m-%d","%Y-%m-%d %H:%M:%S"
-
Currency formats:
- By default currencies will use USD throughout the app, config is coming to change global defaults
- Right now each format can be adjusted to USD, EUR, and GBP
- It's recommended to use explicit currency formatting for now
accounting,usdaccounting,euraccounting,gbpaccounting: $(1,234.50) (usdaccounting_2)currency,usdcurrency,eurcurrency,gbpcurrency: -£1,234.50 (gbpcurrency_2)bigcurrency,bigusdcurrency,bigeurcurrency,biggbpcurrency: €5.60M; €1.23K; €12.23 (biggbpcurrency_2)financial: (1,234.50) (financial_2)- Note financial does not contain a currency mark
groups:
status_groups:
sql: ${order_items.status}
groups:
- filter:
is: [ Cancelled, Returned ]
name: Test
- filter:
is: [ Processing, Shipped ]
name: going
else: Other
label: Status Groups
groups:lets you bucket results with case-like logic by filtering the values of a field into labeled groups.groups:generatesCASE WHEN...SQL statements in the background.- These are only offered for string fields,
bin_boundariesis the equivalent option for numerics (numerics can be cast to string to use groups)
group_label:
name:
group_label: Important Fields
created_at: {}
## field nested under created_at above
example_new_time:
sql: "other_time"
group_label: Created At
timeframes: [minute]
- This will nest a group of fields in the field picker for curated organization
- Omni expects unquoted text (quotes will be removed / ignored)
- Note measures and dimensions will still be in separate sections in the field picker under each view
- Fields can be nested under timeframes using the group label - the text rather than the field should be used (i.e.
Created Atnotcreated_at)
Date dimensions and group labels: By default, date type dimensions will appear in their own group label based on the name of the base dimension with timeframes under the group label appending the timeframe to the group label. If you want to have specific timeframes as standalone dimensions (i.e not under a group) you can accomplish that like this:
created_at_date:
sql: ${created_at[date]}
label: Created at Date
timeframes: []
created_at_month:
sql: ${created_at[month]}
label: Created at Month
timeframes: []
Also note that if you place date type dimensions together under the same group label each timeframe will be displayed without subgrouping. We may support subgrouping of fields in the future.
hidden:
id:
hidden: true
- Remove the field from the UI. Still referenceable in the model, but hidden in the workbook UI.
- Expects 'true' or 'false'
ignored:
_fivetran_deleted:
sql: '"_FIVETRAN_DELETED"'
ignored: true
- Remove the field from the UI, and prevents references to the field
- Often used to 'remove' fields from the raw database schema
- Note ignored fields are still available through the SQL runner
- Expects 'true' or 'false'
label:
full_user_name
label: Full Name
- Label will override the field name for all UI appearances of the field
- Omni expects unquoted text (quotes will be removed / ignored)
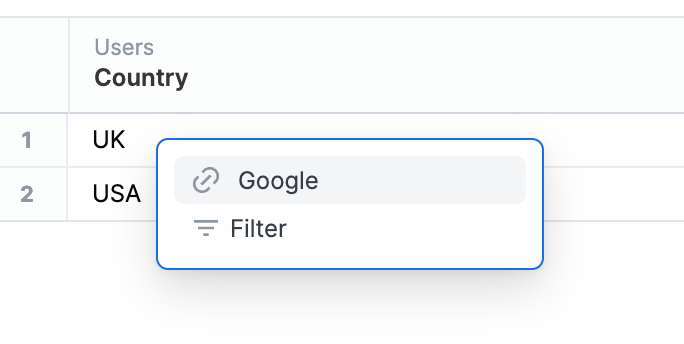
links:
# Example with two links
country:
links:
- url: https://www.google.com/search?q=${users.country}
label: Google
icon_url: https://cdn4.iconfinder.com/data/icons/new-google-logo-2015/400/new-google-favicon-1024.png
- url: https://www.bing.com/search?q=${users.country}
label: Bing
id:
sql: '"ID"'
format: ID
links:
- url: https://sandbox.omniapp.co/dashboards/YX-irW2S/user+lookup?f--users.id=%28%27kind%21%27EQUALS%27%7Etype%21%27number%27%7Evalues%21%5B%27${ecomm__users.id}%27%5D%7Eis_negat*%7Eis_inclus*%29*ive%21false%01*_
label: User Lookup Dashboard
icon_url: https://avatars.githubusercontent.com/u/100505341?s=200&v=4
- Links will add external link to a templated URL into the drill menu
- Omni expects unquoted text, and any field references using
${} - Other fields can be called in a link, and they will be silently added to the query
- Note for crosslinking dashboards (as per example above), you inject the corresponding field into the filter URL structure; it's often easiest to do this from a filtered dashboard and then swapping in the dynamic link
order_by_field:
bin:
order_by_field: bin_order
sql: CASE
WHEN price > 100 THEN 'High'
WHEN price > 20 THEN 'Medium'
ELSE 'Low'
END
bin_order:
sql: CASE
WHEN price > 100 THEN 3
WHEN price > 20 THEN 2
ELSE 1
END
- This will set a field to be ordered by / sort with another field, which will be pulled into any query silently
- Most often used when you want the main field to label buckets that put them in non-alphabetical order
- A common example is our handling of day_of_week (orders by day_of_week_number) or month (orders by month_of_year)
- Omni expects an unquoted field reference
- This can be effective for sorting dynamically grouped fields like duration
primary_key:
id:
primary_key: true
compound_primary_key_field:
sql: concat(${field_1},'-',${field_2})
primary_key: true
hidden: true
- This will set the primary key on a given view
- The primary key is used to prevent fan outs when calculating metrics with more than one table (in conjunction with the join relationship)
- Primary keys can be defined in the workbook layer using the field menu (right click or carrot) and they can also be defined in the model
- Omni expects the value for this parameter to be a boolean (true / false)
- For situations where a database column is not available for
primary_keydeclaration (say compound keys likeCONCAT(id, '-', user_id), it is recommended to created a new field and set that field as the primary key - Alternatively, for compound primary keys, you can set custom_compound_primary_key_sql at the view level to define an array of fields that make up the view's primary key.
- Omni will guess primary key by default for fields labeled
idortable_id(i.e.users_idon theuserstable) - Additionally primary keys can be set automatically using dbt constraints
required_access_grants:
Limits a user's ability to query a field based on an assigned user attribute. The referenced access_grants must already exist in the model file. Refer to the Controlling data access guide for more information.
You can also conditionally allow access by using pipes (|) and commas (,) to create OR and AND conditions.
required_access_grants: [ grant_one ]
# Grant access if conditions are met for either access grant
required_access_grants: [ grant_one|grant_two ]
# Grant access if conditions are met for:
# grant_one
# OR
# grant_two AND grant_three
required_access_grants: [ grant_one|grant_two,grant_three ]
sql:
full_name:
sql: CONCAT(${users.first_name}, ' ', ${users.last_name})
-
The core declaration of the field definition. Best practice dictates using field references over raw database columns when calling other fields/dimensions. Dimensions may only be derived from other dimensions (rather than measures). Other fields can be called wrapping view.name in $, i.e.
${orders.id}. -
Note that field type is implicit in Omni, and defined based upon the underlying fields database type. To change the type, simply CAST the field (for example,
sql: ${zip_code}::string). -
If the sql includes protected words (such as
group), you can include them with the following syntax:"`group`"
DO NOT PARSE
state_sentiment:
sql: |-
-- DO NOT PARSE
SNOWFLAKE.CORTEX.SENTIMENT(${states.state})::float
- DO NOT PARSE is a special argument used in the SQL to stop Omni's parser from interpreting and validating the SQL
- This should be used in the rare circumstance that Omni is not saving valid SQL in the model (usually obscure dialect-specific SQL)
suggest_from_field:
filters:
status:
type: string
suggest_from_field: order_items.status
dimensions:
status_from_an_obscure_subquery:
sql: status_from_an_obscure_subquery
suggest_from_field: order_items.status
- By default, filters will run a
SELECT DISTINCT(${field})to populate filter suggestions - In scenarios where that query may be less performant, or in places where developers may want to curate the suggestion list,
suggest_from_field:can be used to suggest via an alternative field's distinct values - Omni expects a field reference, without
${}, for exampleorder_items.status
suggest_from_topic:
### this will populate suggest from order_items_small topic rather than topic the user is in
status:
suggest_from_field: order_items.status
suggest_from_topic: order_items_small
### this will only suggest USA
country:
suggest_from_field: country
suggest_from_topic: topic_always_where_sql_to_usa
- This parameter can be used to explicitly set the topic of a suggestion field
- By default the suggestion will be done from the current topic, but in cases where performance may need to be optimized the query can be sent to a different, more performant topic or perhaps a topic with some data filtered to reduce load
suggestion_list:
status:
suggestion_list:
- value: Complete
- value: Pending
filter_suggest:
type: string
suggestion_list:
- value: "week"
label: Weekly
- value: "month"
label: Monthly
- By default, filters run a
SELECT DISTINCT(${field})to populate filter suggestions,suggestion_listwill bypass the default behavior suggestion_listcan be used to explicitly set the list of filter options, both for performance reasons, and curation- Values can be selected in the state they appear by simply using
value - Values can also be labeled to improve readability in use cases where the passthrough value may be different than the desired text
tags:
full_name:
sql: CONCAT(${first_name}, ' ' ${last_name})
tags: [pii, secure]
profit:
sql: ${sales} - ${cost}
tags: [finance, secure]
tags:are currently used for field picker search in the workbook and to curatefields:anddrill_fields:- Tags can be referenced (or searched in field picker) within
fields:ordrill_fields:with the syntaxtag:tag_name - In the future, tags will be used to curate the field list, mask fields, or for other security and privacy configuration
- Omni expects an unquoted list using
[]and a comma delimited list of the values
timeframes:
created_at:
sql: created_at
timeframes: [ date, week, day_of_week_name ]
convert_tz: false
- Sets the default time segments available for date / time fields in workbooks
- If absent will use Omni default timeframes: raw, day, week, month, quarter, year
- Timezone handling is possible using the
convert_tzargument. Done in concert with connection-level timezone settings.
Note that date or time fields can reference parametrized timeframes in the model:
timestamp_created_at(the 'raw' reference)timestamp_created_at[date]timestamp_created_at[year]timestamp_created_at[day\_of\_week\_name]timestamp_created_at[month\_name]
Default timeframes: - raw - date - week - month - quarter - year
Additional timeframes (right click in the UI, or can be modeled): - millisecond - second - minute - hour - hour_of_day - day_of_week_name (these will sort by day_of_week_num) - day_of_week_num - day_of_month - day_of_quarter - day_of_year - month_name (these will sort by month_num) - month_num - quarter_of_year
Fiscal timeframes will become available if fiscal_month_offset is applied: fiscal_quarter - fiscal_year. Also note that day_of_quarter will actually behave as fiscal_day_of_quarter.
Custom timeframes can be included using group_label:, with the group_label matching the label rather than the underlying field
## note, "Created At" not "created_at", as the group label must match the label, not the field
created_at_minute_5:
sql: id+1
group_label: Created At
view_label:
lifetime_orders:
sql: user_facts.lifetime_orders
view_label: users
- This will nest a given field under a different view than it's default parent view, for example, grouping
user_factsfields under theusersview for better organization and discovery
Field permissions
In certain situations, you may want to hide or mask values for specific fields. The following pattern can be used combining field logic with User Attributes:
name:
sql: ${users.full_name}
name_hidden:
sql: |+
CASE
WHEN {{omni_attributes.see_names}} = 'true'
THEN ${users.name}
ELSE 'No Access'
END
name_hashed:
sql: |+
CASE
WHEN {{omni_attributes.see_names}} = 'true'
THEN ${users.state}
ELSE MD5(${users.name})
END
Filter-only fields
Filter-only fields are often used alongside templated filters to create fields for more specific use cases that only operate as filters, often to dynamically filter fact tables or subqueries.
Handling schema field adjustments
It's not uncommon that the raw schema has a field name we like, but needs to be adjusted in Omni to work properly for analytics - this can happen due to type casting issues, timezone adjustment, or other more complex reasons. To adjust raw schema fields, you can always leave the field and create a different field like this:
string_that_should_be_number: {}
adjusted_field:
sql: ${string_that_should_be_number}::bigint
Alternatively, you may want to keep the raw field name, and adjust the field in place. For that, simple adjust the SQL on the base field as follows (note no $ on these):
string_that_should_be_number:
sql: string_that_should_be_number::bigint
created_at:
sql: DATETIME(created_at, 'America/Los_Angeles')
JSON parsing
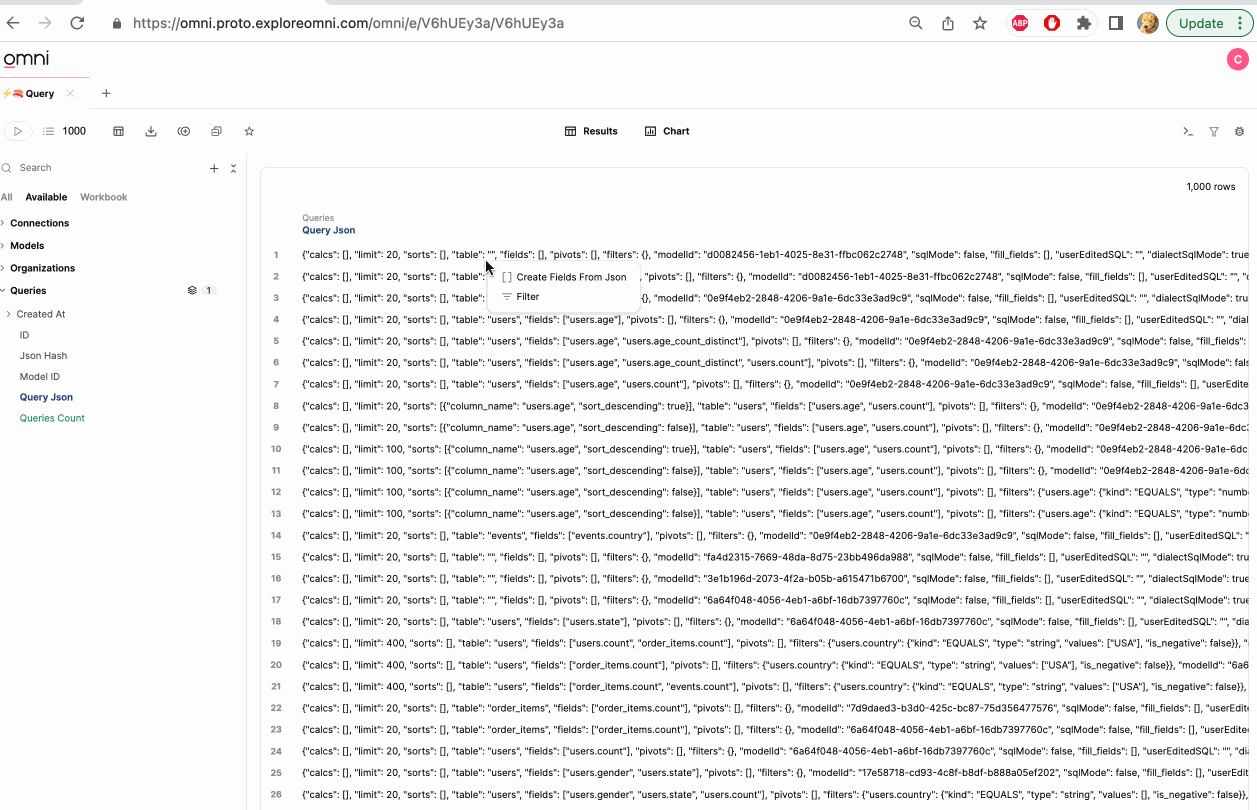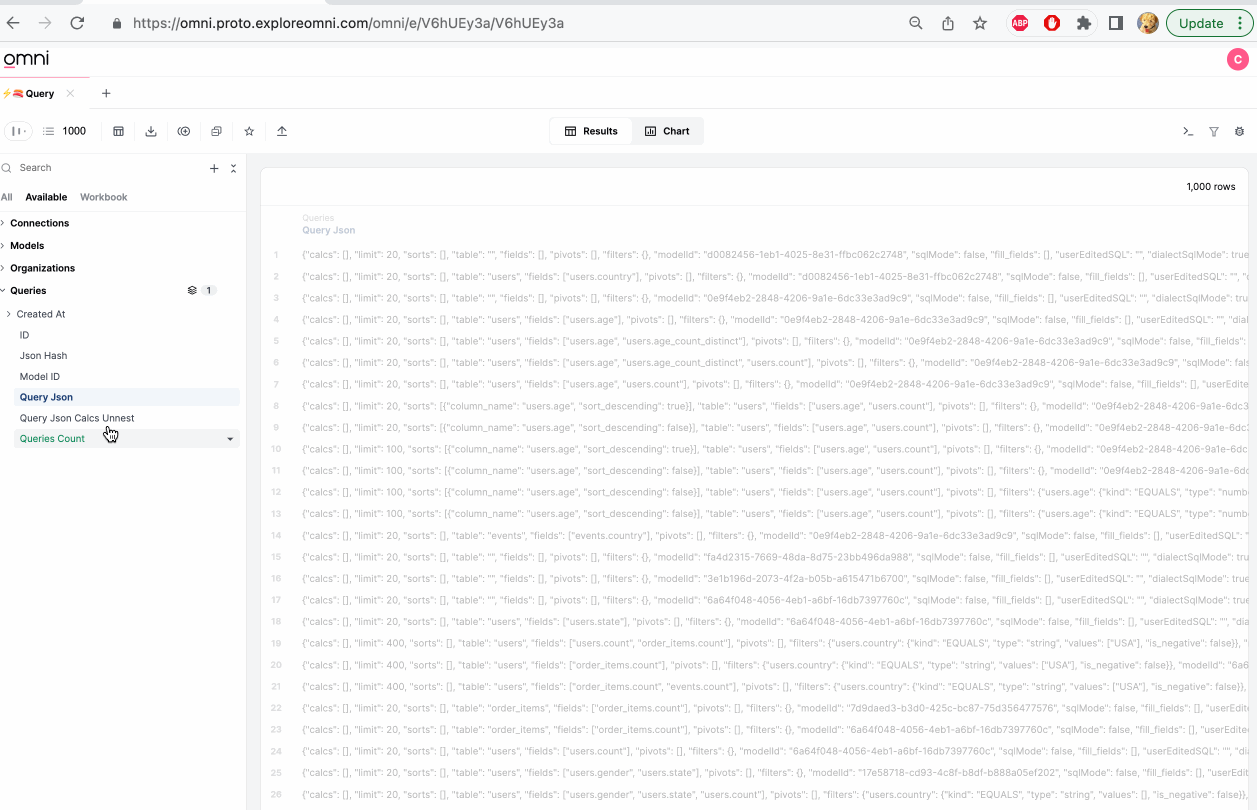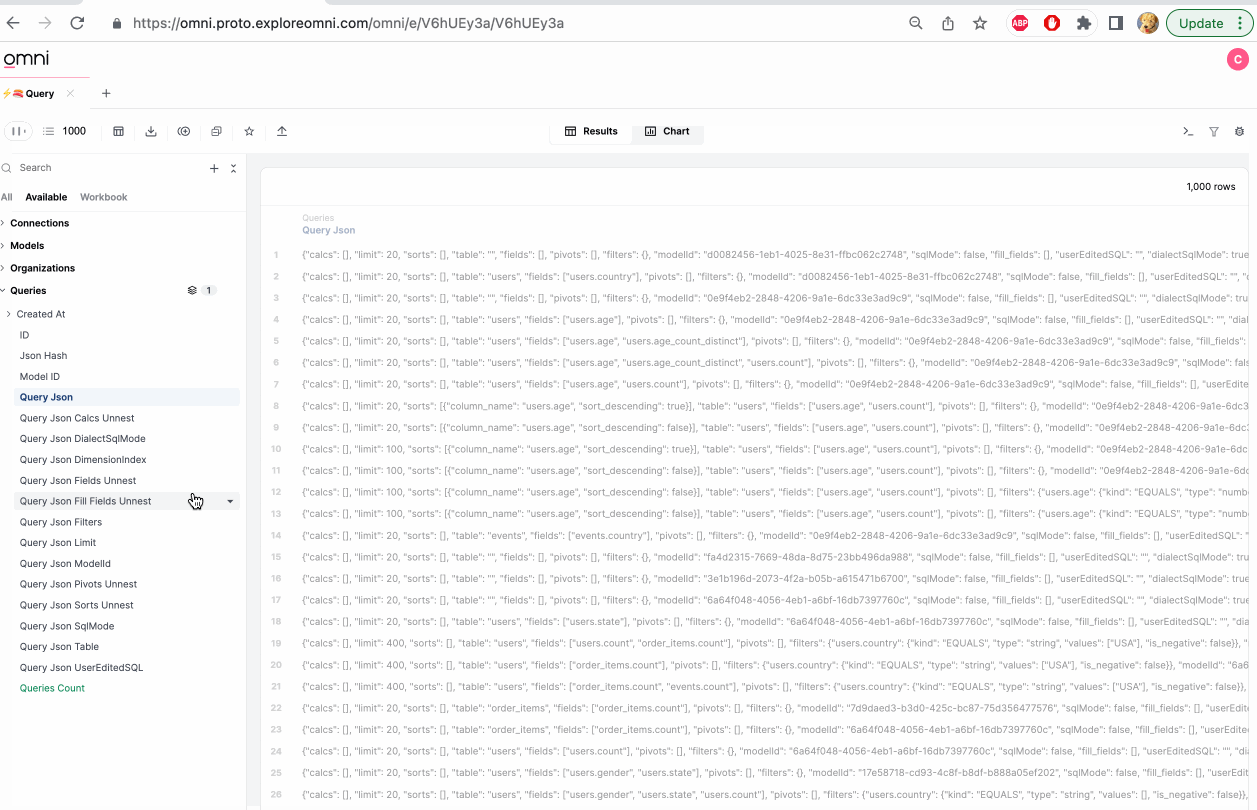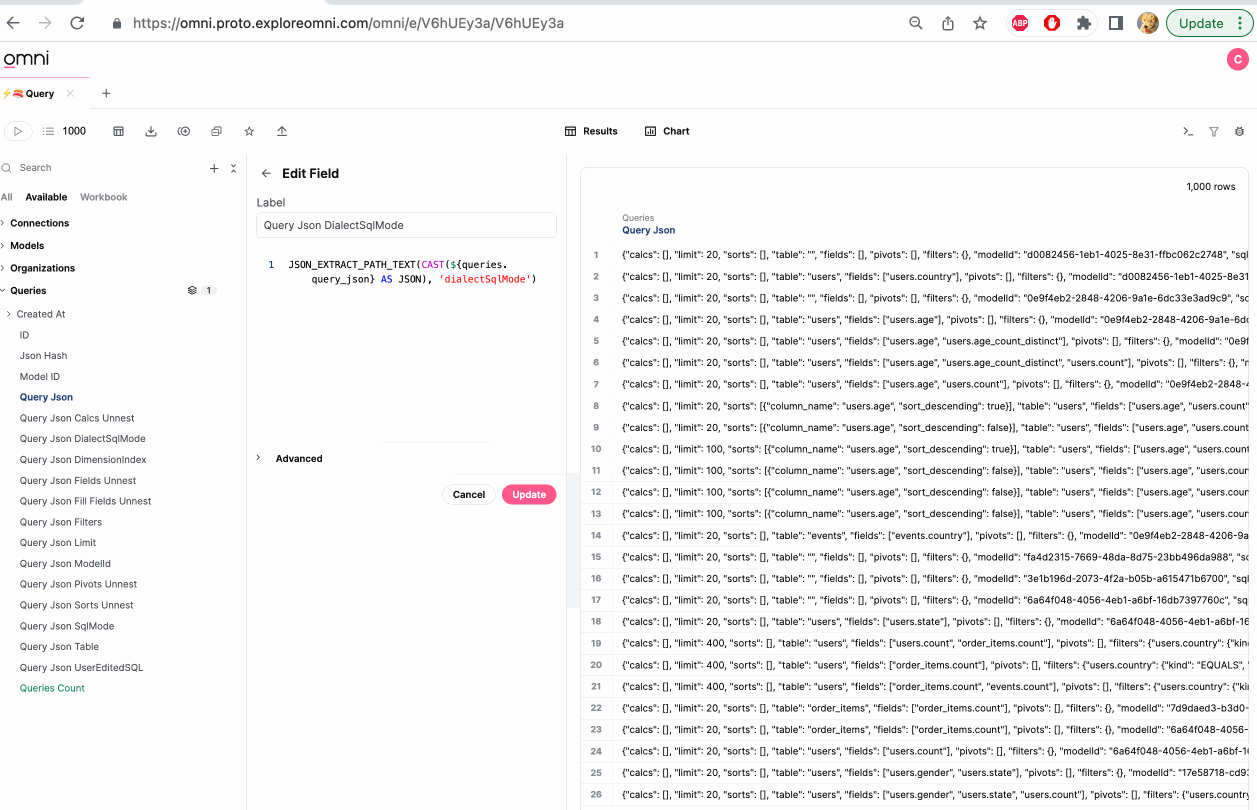
Note that fields recognized as JSON (both true JSON and stringified JSON) can be parsed in the UI. Simply click on JSON results, and recognized nested structures will be offered as instant fields. For now, this is limited to modeled fields, rather than raw SQL. To select more than one field, use shift+click or command+click (see below).
Note that often when parsing JSON the typing may not be as expected (for example timestamps may be created as strings). Be sure to cast the field to the proper type for post-processing.