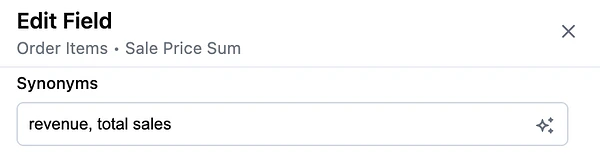
 ### Is it confused between similar fields?
* **Example:** A user asks for “revenue,” and the AI picks the wrong field – maybe it chooses `total_revenue` instead of `net_revenue`.
* **Solve:** Add field [synonyms](/modeling/develop/ai-optimization#curate-views-and-fields) or a more explicit description to help guide selection. If you have duplicative or outdated fields, consider hiding or removing them to simplify the dataset.
### Is it confused between similar fields?
* **Example:** A user asks for “revenue,” and the AI picks the wrong field – maybe it chooses `total_revenue` instead of `net_revenue`.
* **Solve:** Add field [synonyms](/modeling/develop/ai-optimization#curate-views-and-fields) or a more explicit description to help guide selection. If you have duplicative or outdated fields, consider hiding or removing them to simplify the dataset.
 ### Is it picking the wrong dataset?
* **Example:** A user asks about product inventory, but the AI chooses a marketing dataset because of overlapping field names.
* **Solve:** Add more detail to the `ai_context` parameter on each topic, and include examples of real user questions to help the AI learn when each dataset should be used.
```yaml title="product usage topic context" wrap theme={null}
ai_context: |-
this topic contains data about our product usage. the core table is queries, which is the primary concept of usage in our business intelligence product. any question about 'usage' or 'queries' or 'activity' should use this topic
```
### Is there hidden nuance in your business language?
* **Example:** A user asks about “closed deals.” In your org, folks really mean deals that are both closed and won. But without that context, the AI is going to just filter on `closed=true`.
* **Solve:** Clarify how common business terms are used in your `ai_context`, so the AI can apply your team’s language correctly to the data.
**Example**: *if asked about closed deals, most often the user means both closed and won.*
```yaml title="salesforce opportunity topic context" wrap theme={null}
ai_context: |-
we use a fiscal year at our company. when someone mentions 'quarter' or 'year', they typically mean the fiscal quarter or fiscal year
if asked about closed deals, most often the user means both closed and won
```
### Is it picking the wrong dataset?
* **Example:** A user asks about product inventory, but the AI chooses a marketing dataset because of overlapping field names.
* **Solve:** Add more detail to the `ai_context` parameter on each topic, and include examples of real user questions to help the AI learn when each dataset should be used.
```yaml title="product usage topic context" wrap theme={null}
ai_context: |-
this topic contains data about our product usage. the core table is queries, which is the primary concept of usage in our business intelligence product. any question about 'usage' or 'queries' or 'activity' should use this topic
```
### Is there hidden nuance in your business language?
* **Example:** A user asks about “closed deals.” In your org, folks really mean deals that are both closed and won. But without that context, the AI is going to just filter on `closed=true`.
* **Solve:** Clarify how common business terms are used in your `ai_context`, so the AI can apply your team’s language correctly to the data.
**Example**: *if asked about closed deals, most often the user means both closed and won.*
```yaml title="salesforce opportunity topic context" wrap theme={null}
ai_context: |-
we use a fiscal year at our company. when someone mentions 'quarter' or 'year', they typically mean the fiscal quarter or fiscal year
if asked about closed deals, most often the user means both closed and won
```
